AI Progress in Four Charts: A Q2 2026 Brief for Policy Makers and Staff
AI progress has been extraordinarily rapid over the past three years. Language models have moved from failing high-school math problems to contributing to open Erdős problems in ways that leading mathematicians have publicly praised.[1] This brief covers four trends policy makers should understand.
1. AI Progress is Accelerating Exponentially in Programming
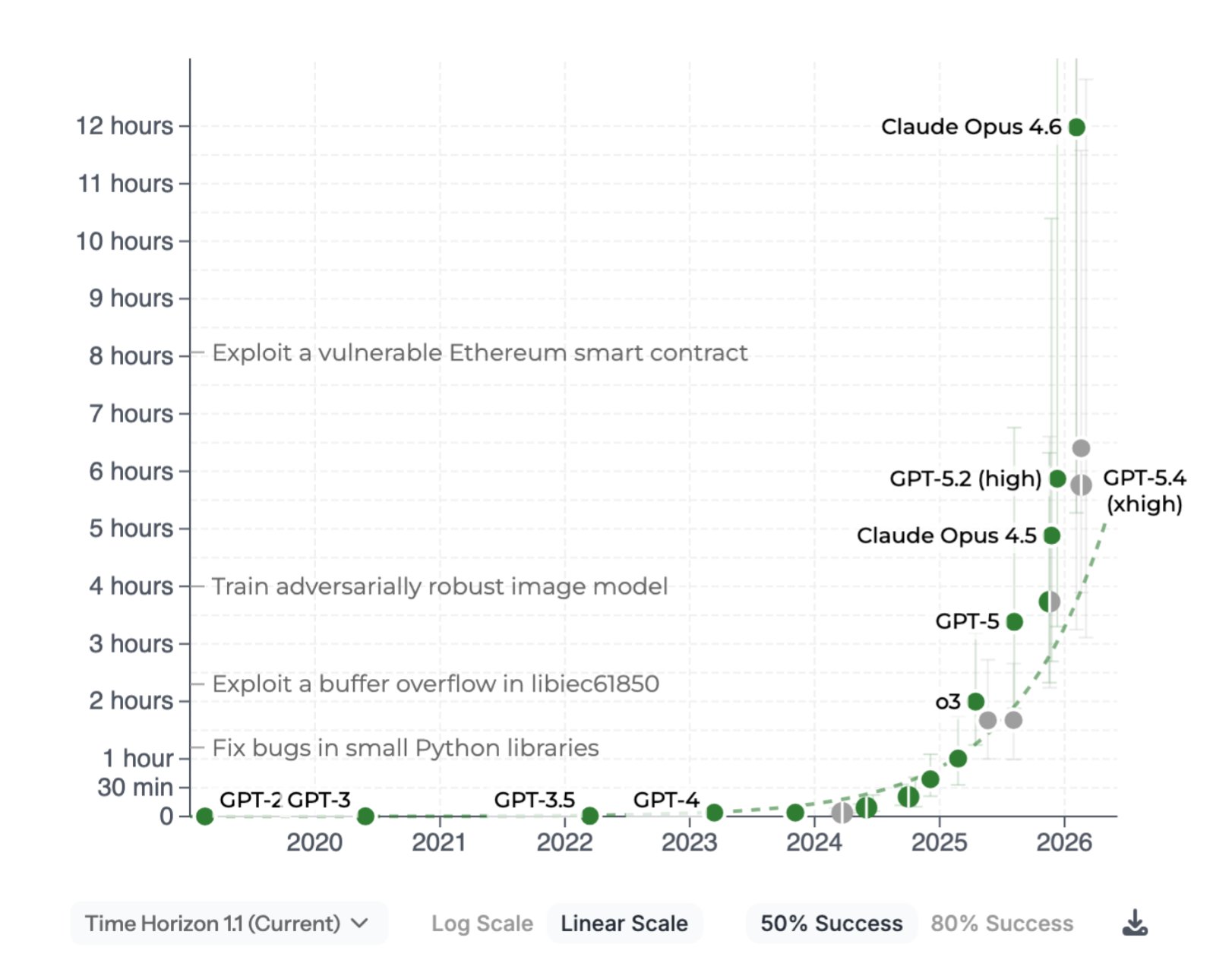
Anthropic, OpenAI, and Google DeepMind are all focused on automating programming in an effort to automate AI research itself. Scaling compute, combined with a technique known as reinforcement learning from verifiable rewards (RLVR), has yielded continual gains in domains where answers can be checked against ground truth: software development, mathematics, and cybersecurity.
METR’s January 2026 update estimates that the time horizon for LLM coding is doubling roughly every 131 days since 2023, a sharp acceleration from the 2019–2025 stitched trend of seven months, and the 2024-onward trend is faster still at 89 days.[2] If this trend holds, by the end of 2026 we will likely have AI agents capable of multi-week programming and cybersecurity time horizons. The rate of doubling may itself increase as AI is used to build the next generation of AI, producing a disorienting and unpredictable speedup.
“We might be 6 to 12 months away from models doing all of what software engineers do end-to-end. I have engineers within Anthropic who say I don’t write any code anymore.”
— Dario Amodei, CEO of Anthropic, World Economic Forum, January 2026[8]
2. Offensive Cyber Capabilities Are Growing Particularly Fast as Coding Improves
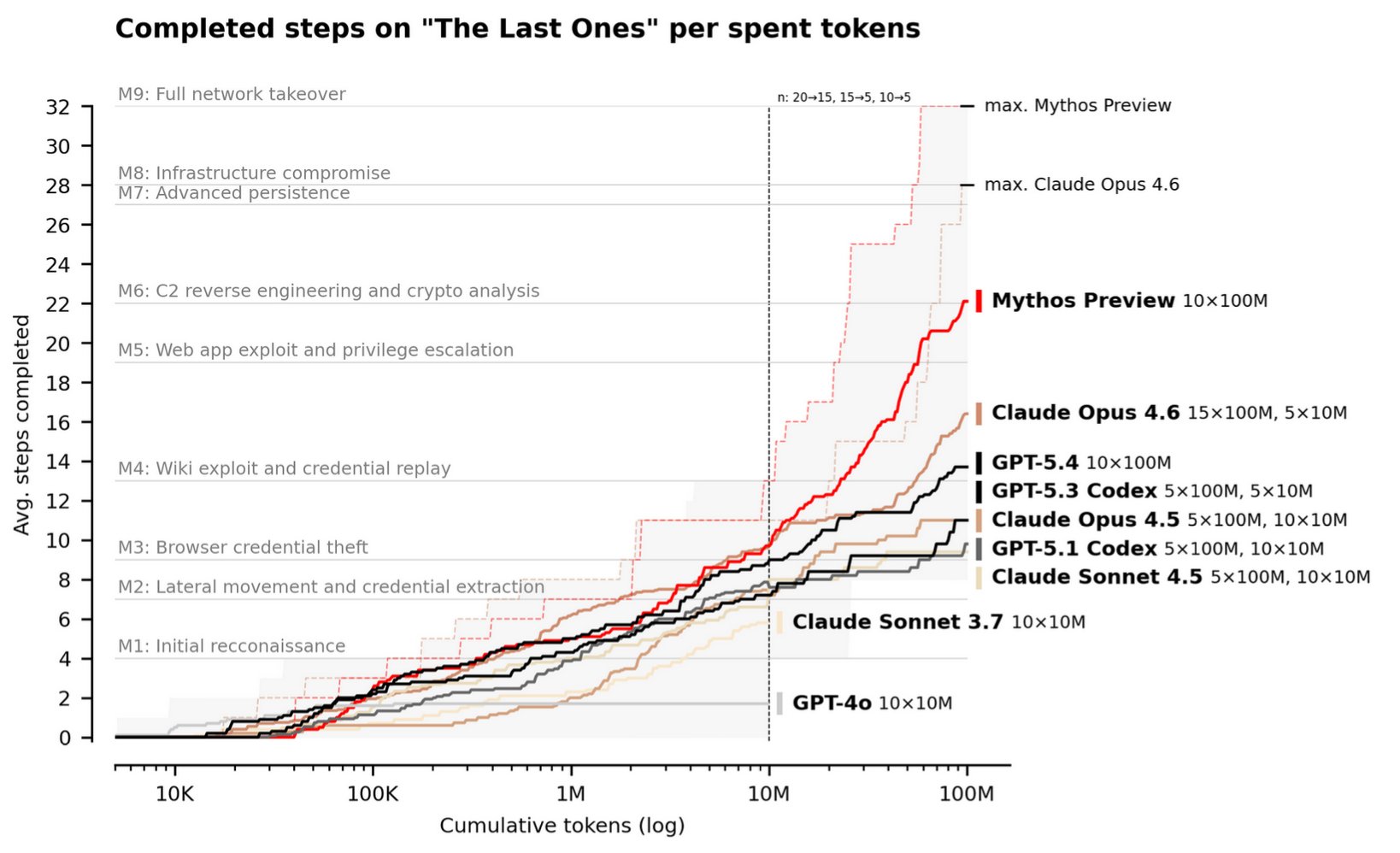
The recent announcement of Anthropic Mythos has shaken the industry.[3] The UK AISI study on Mythos shows that AI is now able to autonomously conduct sophisticated end-to-end cyberattacks against weakly defended systems.[4] As model capability improves and agent harnesses become more sophisticated, AI can take increasingly complicated actions in the real world across compressed time horizons. The primary bottleneck to agentic AI has been lack of reliability on complex multi-step tasks. In software development and cybersecurity, that bottleneck is rapidly dissolving.
“The current systems are getting pretty good at cyber. You need to make sure that the defences are stronger than the offences.”
— Demis Hassabis, CEO of Google DeepMind, India AI Impact Summit, February 2026[9]
3. Open-Weight Models Lag Frontier by 6 to 12 Months
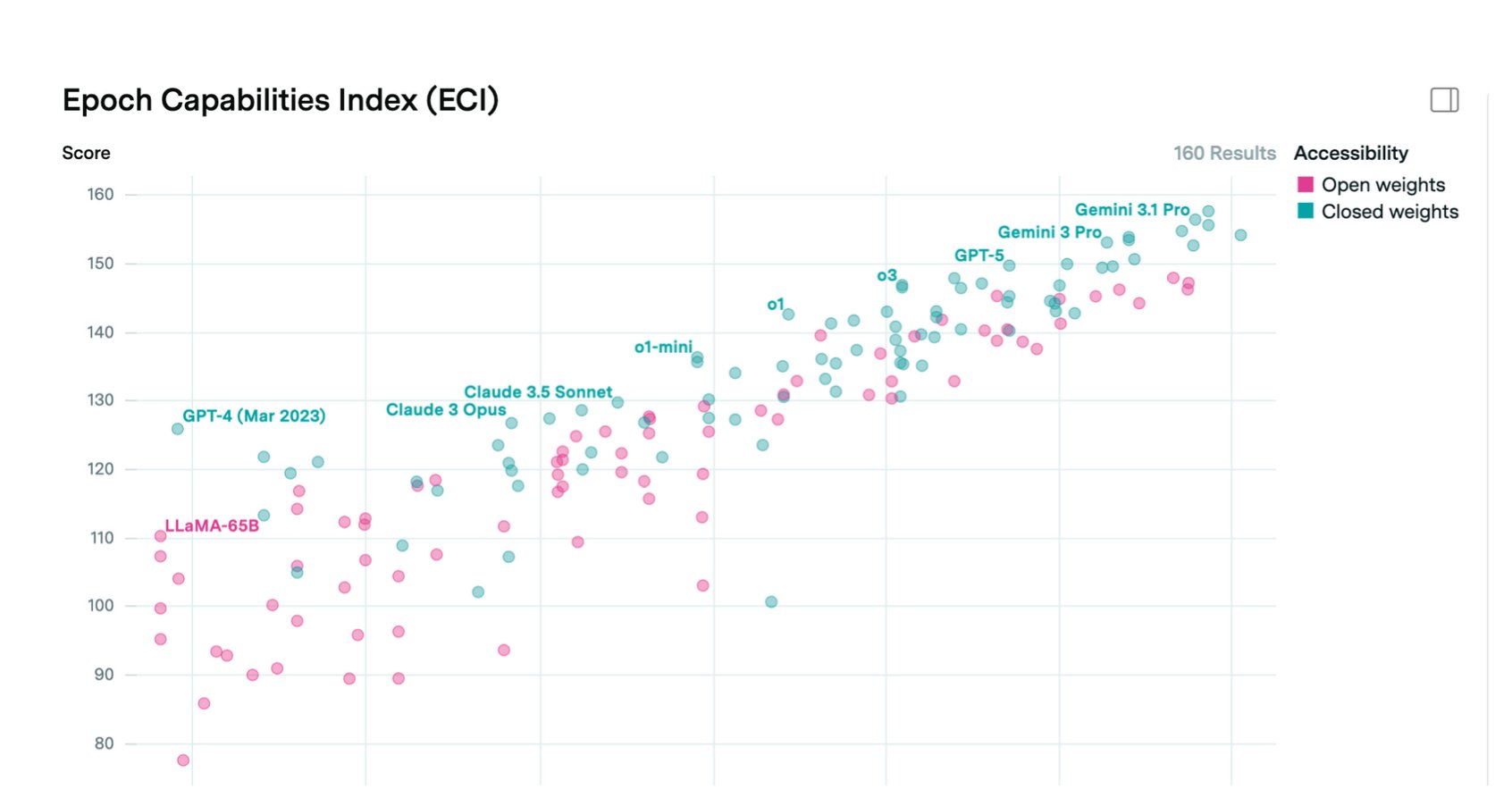
Open-weight models (often called open-source) currently trail proprietary frontier models by roughly 6 to 12 months on capability benchmarks.[5] This means any capability a closed model has today, including Mythos-class cyber capability, we should expect to see in an open-weight model within a year. The implications for cybersecurity, CBRN risk, and financial and cyber fraud are serious.
Open-weight models can be released with safeguards, but those safeguards are trivially easy to strip off through fine-tuning.[6] There is currently no known technical method for releasing open weights in a way that prevents downstream fine-tuning for cyberattacks, bioweapon assistance, or terrorism support. In practice, the capabilities of the best open-weight models should be treated as uncontrollable once released.
“Powerful agentic systems are going to be built, because they’ll be more useful, economically more useful, scientifically more useful. But then those systems become even more powerful in the wrong hands, too.”
— Demis Hassabis, CEO of Google DeepMind, Paris AI Action Summit, February 2025[10]
4. Current Frontier Models Can Substantially Uplift CBRN Threats
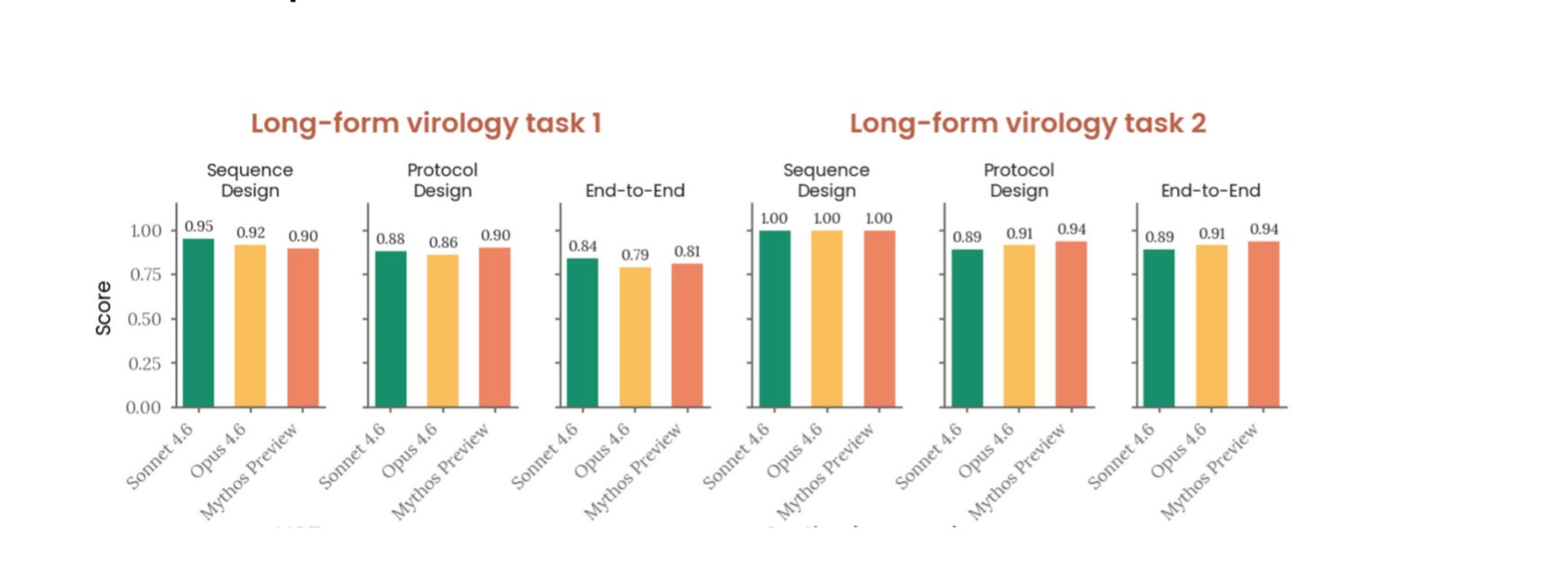
Frontier models are now reaching the point where they can meaningfully uplift malicious actors attempting to create novel CBRN threats.[7] Major model providers invest heavily in safeguards to prevent this, but open-weight models remain only 6 to 12 months behind. Within the next two years, fully open-weight models will likely reach a level where an unskilled actor’s ability to develop a novel biological or chemical threat is materially improved.
OpenAI’s evaluation of GPT-4.5 under its Preparedness Framework found comparable results, rating the model at the boundary of its “Medium” threshold for biological risk.[12] Expert evaluators—credentialed virologists and biosecurity researchers—found that the model could substantially accelerate the information-gathering and protocol-design phases of biological threat development, reducing the time required for a moderately skilled actor to move from intent to actionable synthesis plan. OpenAI noted that while its safeguards reduced compliance on direct requests, adversarial elicitation techniques could recover a significant fraction of the underlying capability. The consistent finding across Anthropic and OpenAI evaluations is that the knowledge required to design novel CBRN threats is now latent in frontier model weights—not as a deliberate design choice, but as an emergent consequence of training on the world’s scientific literature. Safeguards reduce willingness; they do not reduce capability.
“As of mid-2025, our measurements show that LLMs may already be providing substantial uplift in several relevant areas, perhaps doubling or tripling the likelihood of success. We believe that models are likely now approaching the point where, without safeguards, they could be useful in enabling someone with a STEM degree but not specifically a biology degree to go through the whole process of producing a bioweapon.”
— Dario Amodei, CEO of Anthropic, “The Adolescence of Technology,” January 2026[11]
Concluding Thoughts
Taken together, these four trends are an urgent call to action for global policy makers. The time to regulate is before a major cyber or biosecurity incident, not after.
- AI capability is demonstrably increasing, and the rate of that increase is itself growing.
- Proprietary frontier models can now conduct end-to-end complex cyberattacks and routinely discover zero-day vulnerabilities.
- Any capability in a closed model is likely to appear in an open-weight model within 12 months.
- Frontier models can now substantially uplift threat actors for CBRN risks.
Humans waited for nuclear and airline disasters before regulating those industries. Waiting for an AI disaster to regulate AI is a losing proposition that could cause enormous loss of life, significant financial harm, or even an existential catastrophe.
Footnotes
1 Terence Tao, Mathstodon post on Erdős Problem #728, January 8, 2026: mathstodon.xyz/@tao/115855840223258103. Tao notes this is the first Erdős problem solved “more or less autonomously” by AI (GPT-5.2 Pro, with proof formalized in Lean via Harmonic’s Aristotle) in a way not previously documented in the literature. Tao estimates only 1–2% of open Erdős problems are currently tractable to AI with minimal human assistance. ↩
2 METR, “Time Horizon 1.1,” January 29, 2026: metr.org/blog/2026-1-29-time-horizon-1-1. The 131-day doubling applies to the post-2023 trend under the updated TH1.1 methodology. The 2019–2025 stitched trend is 196 days (roughly seven months); the 2024-onward trend is 89 days. ↩
3 Anthropic announced Claude Mythos Preview on April 7, 2026. See also Anthropic, “Project Glasswing: Securing critical software for the AI era”: anthropic.com/glasswing. ↩
4 UK AI Security Institute, “Our evaluation of Claude Mythos Preview’s cyber capabilities,” April 2026: aisi.gov.uk. AISI found Mythos Preview “at least capable of autonomously attacking small, weakly defended and vulnerable enterprise systems where access to a network has been gained,” while cautioning that test environments were deliberately simplified. The UK government subsequently issued an open letter urging executives to invest in cyber defense, citing this finding. ↩
5 Epoch AI Capabilities Index (ECI): epoch.ai/benchmarks and Epoch AI, “Open vs. closed AI: How behind are open models?”: epoch.ai/blog/open-models-report. Epoch finds open-weight models lag closed-weight by an average of roughly one year (90% CI: 5–22 months depending on benchmark). See also Nathan Lambert, “What comes next with open models,” Interconnects: interconnects.ai, placing the gap at 6–18 months historically. ↩
6 Tamirisa et al., “Tamper-Resistant Safeguards for Open-Weight LLMs,” arXiv:2408.00761: arxiv.org/abs/2408.00761 (“refusal and unlearning safeguards can be trivially removed with a few steps of fine-tuning”). See also OpenAI’s worst-case analysis for gpt-oss: openai.com (PDF), which demonstrates that anti-refusal fine-tuning can drive refusal rates on unsafe prompts to near zero while preserving benchmark performance. ↩
7 Anthropic Claude Opus 4 System Card and ASL-3 activation: in a bioweapons acquisition uplift trial, Opus 4 produced a 2.53x uplift over internet-only controls, which Anthropic described as “suitably close that we are unable to rule out ASL-3.” Subsequent Claude Opus 4.5 evaluations showed expert-level uplift trials where participants produced substantially higher scores and fewer critical errors with model assistance. See Anthropic Transparency Hub: anthropic.com/transparency and “Strategic warning for AI risk”: anthropic.com/news. ↩
8 Dario Amodei, CEO of Anthropic, speaking at the World Economic Forum in Davos, January 2026. Reported in Yahoo Finance / Benzinga, “Anthropic CEO Predicts AI Models Will Replace Software Engineers In 6–12 Months” (January 22, 2026): finance.yahoo.com. ↩
9 Demis Hassabis, CEO of Google DeepMind, speaking at the India AI Impact Summit, February 2026. Reported in Outlook Business, “We are at a threshold moment where AGI is on the horizon” (February 18, 2026): outlookbusiness.com. ↩
10 Demis Hassabis, CEO of Google DeepMind, speaking with Axios at the Paris AI Action Summit, February 2025: axios.com. ↩
11 Dario Amodei, “The Adolescence of Technology: Confronting and Overcoming the Risks of Powerful AI,” January 2026: darioamodei.com. ↩
12 OpenAI, “GPT-4.5 System Card,” February 2025: openai.com/index/gpt-4-5-system-card. Under OpenAI’s Preparedness Framework, CBRN risk is scored Low/Medium/High/Critical; GPT-4.5 was rated Medium for biological and chemical risks, with evaluators noting “some meaningful uplift” for acquiring CBRN-relevant information and constructing synthesis plans. See also OpenAI Preparedness Framework: openai.com/safety/preparedness. ↩